TensorFlow 是 2015 年年底开源的一套深度学习框架,是目前最活跃的深度学习框架。本文基于 2.0 版本,首先介绍它的安装和基本用法,然后讨论了深度学习的基本概念,包括神经网络前向计算、损失函数、反向传播计算和优化函数等,接着介绍了卷积神经网络和循环神经网络,最后介绍了在大规模应用的场景下,如何实现分布式的深度学习训练。
安装 Tensorflow 环境
# 安装python3,pip
sudo yum -y install epel-release
sudo yum -y install gcc gcc-c++ python3-pip python-devel atlas atlas-devel gcc-gfortran openssl-devel libffi-devel
#更新python国内源
mkdir ~/.pip
vim ~/.pip/pip.conf
[global]
index-url = https://pypi.mirrors.ustc.edu.cn/simple/
[install]
trusted-host = mirrors.ustc.edu.cn
# 安装virtualenv
pip3 install --upgrade virtualenv
virtualenv --system-site-packages ~/venvs/tensorflow
curl
sudo python get-pip.py
pip --version
sudo pip install virtualenv
virtualevn --version
# 创建python虚拟环境
virtualenv --system-site-packages -p python2.7 ./venv
# 激活虚拟环境
source venv/bin/activate
# 安装Tensorflow
pip install -i http://mirrors.aliyun.com/pypi/simple/ tensorflow
# 查看安装的软件
pip list installed
#通过python交互式环境验证安装是否成功
python
import tensorflow as tf
exit() //退出python交互环境
deactivate //退出python虚拟环境Helloworld 示例验证
source venv/bin/activate
python //进入python交互式环境
import tensorflow as tf
hello = tf.constant("hello tensorflow.)
sess = tf.Session()
sess.run(hello)在 Jupyter 交互式环境中使用 Tensorflow
pip install jupyter
python -m ipykernel install --user --name=venv
jupyter kernelspec list
jupyter notebook //自动打开浏览器在 Docker 中使用 Tensorflow
docker pull tensorflow/tensorflow:nightly-jupyter
vim docker-compose.yml #制作配置文件
docker-compose up -d #初次启动,以后用start/stop
docker exec -it xxxx bash #进入docker,然后执行如下命令升级安装Python3
apt-get update
apt-get install python-software-properties
apt-get install python3.6
apt install python3-pip
#更新python国内源
mkdir ~/.pip
vim ~/.pip/pip.conf
[global]
index-url = https://pypi.mirrors.ustc.edu.cn/simple/
[install]
trusted-host = mirrors.ustc.edu.cn
#在jupyter中启用python3
jupyter kernelspec list # 查看激活的kernel
python3 -m pip install ipykernel
python3 -m ipykernel install --user
rm /usr/local/bin/python
ln -s /usr/bin/python3.6 /usr/local/bin/python
python --version #显示Python 3.6.x,则安装成功
pip install --upgrade tensorflow jupyter matplotlib pandas seaborn numpy tensorflow-hub tensorflow-datasets pillow
pip list installed- 使用 docker-compose 管理容器
version: '3'
services:
tensorflow-jupyter:
image: tensorflow/tensorflow:nightly-jupyter
ports:
- "8888:8888"
- "6006:6006"
volumes:
- .:/tf/notebooks启动: docker-compose up
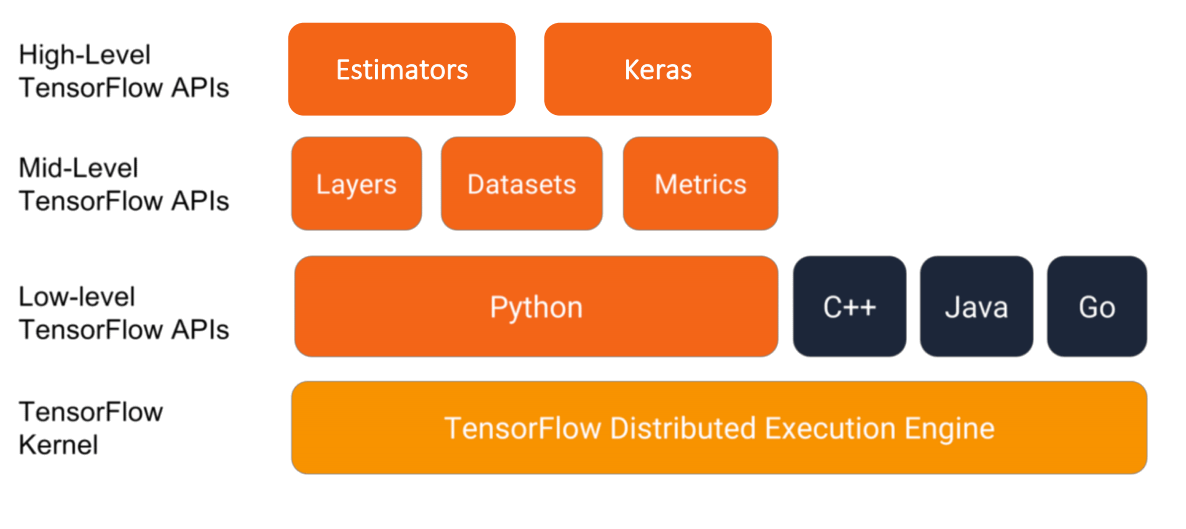
Tensorflow 架构介绍
实战:使用 CNN 识别彩色尺寸各异的猫狗图片
参考 Colab
扁平化处理
调整尺寸为一致的 150 * 150,以便可以生成相同大小的一位数组
彩色图像处理
使用三维数组建模,增加 RGB 作为 3 维数组的深度值,如图:
对彩色图像执行卷积运算
- 将彩色图像分解为 3 维数组

- 利用三个过滤核进行卷积运算示例

- 示例中使用三个三维过滤器进行卷积运算

- 代码说明
tf.keras.layers.Conv2D(filters, kernel_size, ...) # 参数:过滤器数量, 卷积核形状, ...
#本例中使用:
tf.keras.layers.Conv2D(3, (3,3), ...) 在训练 CNN 时,将通过损失函数更新三维核中的值,从而最小化损失。
执行最大池化运算

最大池化处理后,获得的三维数组宽度和高度减半,但深度不变。
使用验证集解决过拟合问题(早停法)
通常在完成训练后,在测试集上进行验证才能发现过拟合问题。可以通过增加验证集,在每轮训练过程中基于验证集检查效果,分析训练损失和验证损失与周期的函数图,可判断出模型泛化效果。

可以看出,验证集有助于我们判断 CNN 应该训练多少个周期,即可以达到较好的训练效果又不会出现过拟合,提前结束训练一遍获取最优模型。对于有多个潜在模型可选择时(如为模型选择合适的参数/结构),也可以用这种方法对比选择最优模型。
如果训练集足够广泛(如各种各样可能的图片都有,如大小,位置,猫狗完整性等),将有助于训练出泛化能力强的模型。
使用图像增加技术避免过拟合
通过应用各种图片变换,可以增加样本数量,提高泛化能力避免过拟合的效果。

使用随机丢弃避免过拟合(仅限深度神经网络)
丢弃是指在训练过程中,随机关闭网络中的某些神经元。可以强制其它神经元产生更大的影响,在训练中扮演积极角色,如图:

在实践中,会指定每个训练周期每个神经元被丢弃的概率。
实战: 图片增强的狗与猫图片分类
参考Colab,我们将遵循一般的机器学习流程:
- Examine and understand data 检查和理解数据
- Build an input pipeline 构建输入管道
- Build our model 建立我们的模型
- Train our model 训练我们的模型
- Test our model 测试我们的模型
- Improve our model/Repeat the process 改进我们的模型 / 重复这个过程
其它避免过拟合的技巧
收集更多数据及添加噪音:这和数据增强的目的是一样的,但是也会使模型对于自然界中可能遇到的干扰更加稳定。
简化模型:通过逐步降低模型的复杂性ーー随机森林中估计值的数目、神经网络中参数的数目等ーー你可以使模型足够简单,不会过度拟合,但也足够复杂,可以从你的数据中学习。 要做到这一点,根据模型的复杂性来查看两个数据集上的错误是很方便的。
改变训练方式:包括改变损失函数,或者模型在训练期间的工作方式。
正则化:正则化是一个约束模型学习以减少过拟合的过程。 其中一个最强大的和众所周知的技术正则化是增加一个惩罚的损失函数。 最常见的是 L1 和 L2。L1 惩罚的目的是最小化权重的绝对值,这有助于识别数据集中最相关的特性。L2 惩罚的目的是使权重的平方最小化,效率高于 L1。通过惩罚,该模型被迫在权重上做出妥协,因为它不能再将权重任意增加。 这使得模型更加通用,有助于防止过拟合。
练习:增加版花朵图像分类
参考:自行练习版 Colab,官方版 Colab
迁移学习
基础知识
迁移学习的原理是通过使用由机器学习专家创建的经过大型数据训练过的模型,将模型已经学习到的知识迁移到新的数据集上,可以显著提高预测准确率。如上面猫狗识别的实战可以将准确率从 80%提高到 95%

在迁移学习中,预训练的模型中的参数将被冻结(避免随机初始化权重),只训练最后分类层级的变量,可以显著提高训练速度。

示例代码:

参考 Colab:对猫狗数据集应用迁移学习 , 通过迁移学习分类花朵图像
实战:房价预测(线性回归)
基础知识


matplotlib 是一个 Python 2D 绘图库,可以生成出版物质量级别的图像和各种硬拷贝格式,并广泛支持多种平台,如:Python 脚本,Python,IPython Shell 和 Jupyter Notebook。
seaborn 是一个基于 matplotlib 的 Python 数据可视化库。它提供了更易用的高级接口,用于绘制精美且信息丰富的统计图形。
mpl_toolkits.mplot3d 是一个基础 3D 绘图(散点图、平面图、折线图等)工具集,也是 matplotlib 库的一部分。同时,它也支持轻量级的独立安装模式。
NumPy 是一个 BSD 开源协议许可的,面向 Python 用户的基础科学计算库,在多 维数组上实现了线性代数、傅立叶变换和其他丰富的函数运算。




